CMU Dataset
The CMU Dataset contains both plot summaries and Metadata about the movies. It contains 81741 entries. The Metadata includes Movie Runtime, Box Office Revenue, languages, movie genres, countries, release date, Wikipedia Page ID. Movie years range from 1897 to 2016.
Bechdel Dataset
The Bechdel Dataset is downloaded from the webpage https://bechdeltest.com. It gives the result of the Bechdel Test for 10136 movies, as well as release year and IMDB page ID. This database is constantly supplied, and verified by users. It is assumed in the present study that the database is fully reliable, and that the the diversity of users who contribute to the database makes it robust.
CPI Dataset
We downloaded Consumer Price Indices from the OECD site. These indices represent the relative price for a representative basket of goods and services over a certain period. We chose to use yearly data from the United States, meaning we had indices going back almost 70 years to 1955.
This data complemented our existing datasets nicely, as all box office revenues in the CMU Dataset are quoted in USD, and for most all movies we have the year of release, whereas we only have specific months and days for a lesser subset.
It is possible to manipulate the CPI in order to obtain inflation coefficients from each year in the past to the most recent year in the dataset, 2022. The formula we employ is as follows :
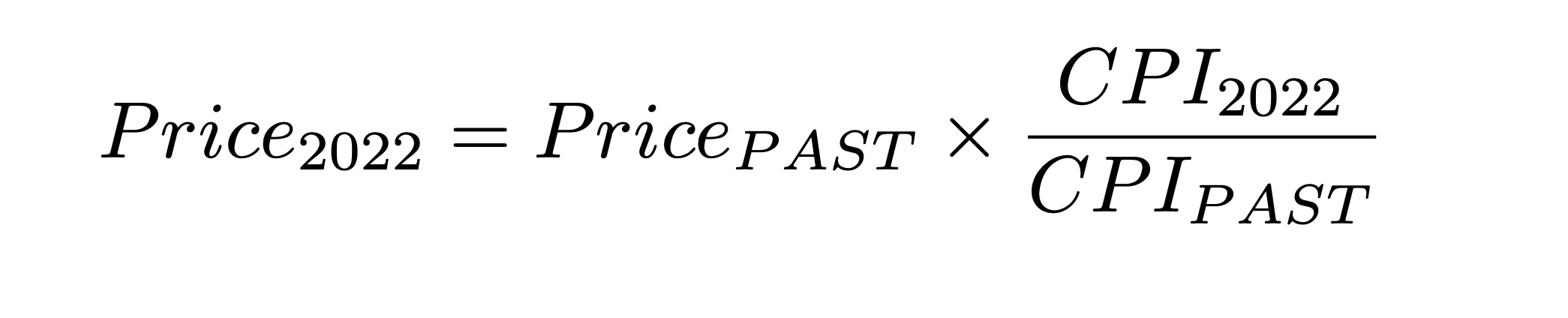
Merging the two
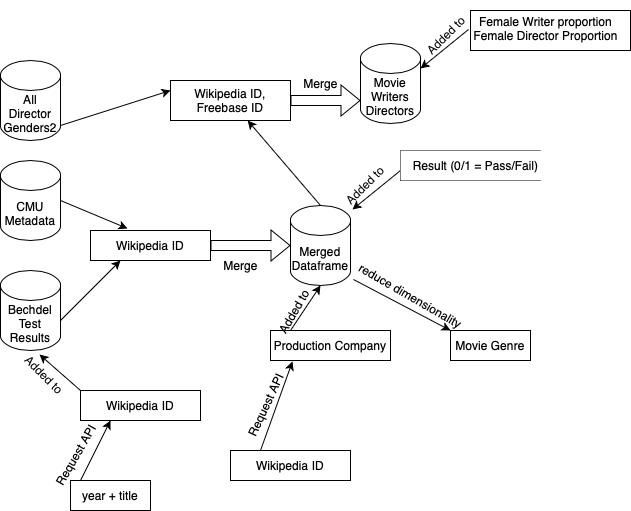
The CMU Metadata dataframe and Bechdel dataframe do not have a common column of identical unique IDs on which the merge could be performed. It was therefore necessary to request the Wikipedia Page IDs from Movie title and year from the Bechdel data. Then, the two dataframes were merged on those IDs, creating a merged dataset of 5816 movies (57 % of Bechdel movies are in the merged dataset). The obtained merged dataframe is large enough to perform statistical analysis.
Representativeness of the data
The CMU dataset contains films up to 2017, while the Bechdel database contains films up to the latest Box Office releases. It will not be possible to look at the five past years, although these years may be among the most interesting in the present study, since the movie industry has evolved very fast with MeToo and Netflix among others. The study carried out here will be mainly representative of the years 2005-2012, which corresponds to the peak of films from the two data sources.
Another notable bias within the dataset, is that of country. Indeed, our data and thus our results will be most representative of the American film industry. Given that the CMU Movie Corpus was developed at an American university and the Bechdel test proposed by an American woman, this bias was to be expected. Bar American movies, Western culture in general is vastly over-represented in our data.
Both datasets have similar percentages of scores on the Bechdel test, meaning that they represent a similar subset of movies when it comes to the test.